
EBS 교재 수요분석
빅데이터 FARM, EBS 산학 협력 프로젝트에서 진행된 내용입니다.
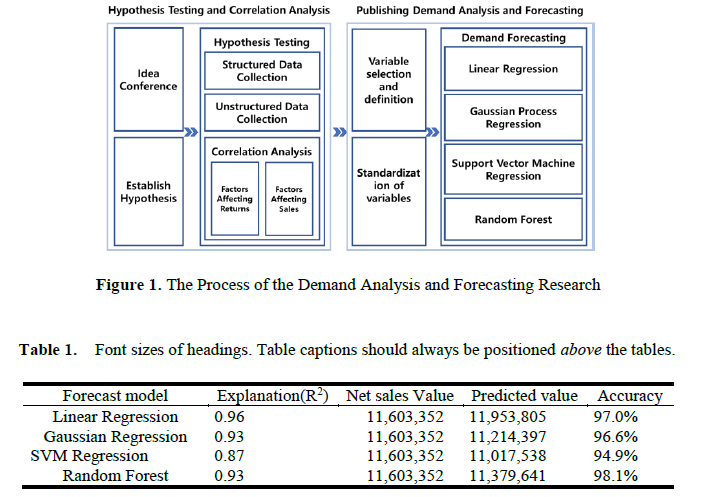
프로젝트는 14명 정도의 인원으로 진행해서 관련 부분에 잘 모르더라도 참여하는데 부담감이 없었다. 그러나 실제로 프로젝트를 진행하면서 필요한 지식들이 많아져서 수업들을 때보다 훨씬 더 공부를 많이하게 됐다. 기한과 책임감이 있어야 성장하는데 도움이 된다는 걸 알고 프로젝트 기회가 있다면 계속해서 참여하게 되는 계기가 되었다. 처음엔 EBS의 반품률을 단순히 분석해서 반품률을 줄여달라는 요구였다. 지난 학기에도 다른 팀이 같은 내용으로 진행했었는데 그 팀은 아쉽게도 수험생 숫자와 연관이 있어보인다 정도의 의미없는 수준의 결과만 보여주었다고 한다. 이 때 이번 프로젝트가 상당한 난이도를 갖고 있다는 걸 알게 됐다. 주어진 정보가 적어서 였는데 그건 교재별 판매량과 반품률 정도밖에 없었으며, 각 자료의 양식이 연도마다 달랐다. 또한 목표는 반품률을 줄여달라였으니 최대한 수요에 가깝게 예측하여 발행하여야 한다. 그렇기 때문에 실제로 판매 될 순출고를 정확히 맞추면 된다는 가정을 세워 최종 목표는 순출고 예측으로 바꾸게 되었다.
처음엔 교수님과 함께 14명의 팀원은 각자가 가진 생각을 바탕으로 반품률에 영향을 줄 수 있는 여러 가설들을 뽑았다. 의외의 데이터가 연관이 있을 수 있다는 생각에 각 지역별 고교생 수, 날씨 등 여러가지 데이터를 수집하기로 했다. 데이터 수집 과정에 상당한 수작업이 필요했고, 그 중에 일부는 데이터를 가져온다해도 실제로 연관 짓기 힘들것 같다는 생각이 들어 중간에 포기한 데이터들이 많았다. 이러한 과정을 거쳐서 확실히 뽑기로 정한 자료는 수험생 숫자, 수능 난이도, 인터넷 강의 수강후기 수, 교재별 긍부정 데이터, 검색량 및 조회수이다. 대부분의 자료들을 수작업으로 획득하였으나, 긍부정 평가와 검색량, 수험생 사이트 조회수에 쓰인 데이터는 크롤링을 통해서 수집하였다.
또한 각 교재가 갖고 있는 시리즈가 판매량에 큰 영향을 끼칠 것이라는 가설을 설정하여 시리즈 변수를 만들었다. 또한 수집한 수강후기 수를 바탕으로 가장 높은 수강후기 수를 보유하고 있는 강사를 영역별 최고 강사로 선정하였다. 그 강사가 특정 교재를 강의한다면 그 교재의 판매량과 분명 연관이 있을 것이라는 가설을 세웠다. 기나긴 수험생활 동안 Top 강사가 수험생에 미치는 영향력이 엄청났다는 경험에서 세운 가설이다. 수능 교재 수능 연계 여부, EBS는 교재 특성상 해마다 같은 이름의 교재를 새로 출판하는데, 이러한 교재를 비연속 교재라고 하고 2~3년간 같은 교재인 것을 연속 교재라고 한다.
데이터 수집 과정에서 상당한 시간을 소요하였는데 전체 프로젝트 기간 중 60%정도이다. 기존의 데이터가 부족한 점을 고려했을 때 데이터 수집이 중점적으로 되어야 하는 것은 맞았지만 사용할 수 있는지 판단하는 과정도 중요했다.
그렇기 위해서 데이터 전처리 과정을 통해 어떤 변수가 쓰일 수 있는지 판단하고자 다양한 변수와 결합하거나 범주형, 숫자형 등으로 바꾸어 나갔고, 수 크기의 범위를 조정해나갔다.
상관도 분석을 통해서 새롭게 수집한 수능 난이도가 교재 반품률과 크게 연관이 있었다. 전체적으로 작년 수능이 어려울수록 그 해 교재 수능 연계 교재 판매량은 상승했다. 이러한 결과를 얻기 위해서 수능 난이도 수집과 그리고 수능 난이도를 적절하게 수치화해서 등급화하는 과정이 필요했다. 5개 등급으로 나누어서 숫자형 데이터로 집어넣어서 사용하였다.
다중 공선성을 판단해서 몇 개의 변수는 제거하여 사용하였다. 회귀 분석, 가우시안 과정 회귀, SVM, Random Forest, 다중 트리 등을 이용하여 순출고 예측하였고 실제로 R2-score가 꽤나 높게 나와서 상당히 의미있는 결과를 암시했다.
잔차 분석을 통해서 충분히 의미가 있는 모델임을 확인하고 보고서를 작성해 나갔고, 이를 바탕으로 EBS에서 임원진과 실무진 앞에서 발표를 진행하였다. 실무진이 기존에 하던 프로세스는 총판회사가 원하는 수요보다 조금 못 미치게 주는 방식으로 하여 수요를 맞추는 방식이었다. 다만, 이러한 분석 기법을 기존의 직원들이 진행하긴 힘들다는 점 때문에 바로 이용하지 않는다곤 하였으나 수능 난이도 등의 상관도 분석을 통해 얻어낸 결과는 유의미하게 쓰일 것 같다고 하였다.
어려웠던 점은 워낙에 dataset이 적어서 train/test set을 나눌 때 적절한 test셋을 선정하기 힘들었다. 실제로 test하기위해선 EBS에서 직접 시행하여야 하나 데이터가 아직 마련되어 있지 않아 바로 시행하진 못하였다.
기존의 출고부수가 순출고 부수보다 10% 높게 출고되어 원래도 상당히 정확한 편에 속한다. 그럼에도 반품비를 줄이라는 요구가 들어와 본 프로젝트를 진행하였는데, 이렇게 제작한 모델을 사용한다면 순출고와 5%정도만 차이나게 출고할 수 있어서 반품비를 단순히 생각하면 50% 정도 줄일 수 있다. 매년 발생하는 50억에서 80억 가량의 반품금액을 25억에서 40억 사이로 줄일 수 있다는 것이다. 다만, 각 지역 서점에 예비해야할 양을 고려했을 때 정확히 절반 가량의 반품을 줄이기보다는 30%정도인 35억~56억을 최종 반품비로 예측하고 있다.
정량적인 평가 방식이 실제 업무에 도움이 되어 꽤나 큰 이익과 직결된 결과를 만들 수 있어서 굉장히 의미가 있게 다가왔다. 수업을 통해서 이론을 공부할 때와 달리 실제 목표에 맞추어서 학습을 하다보니 어떤 도메인이 필요한지 알게 되어 다음의 커리큘럼을 짜는 데에 큰 도움이 되었다. 그리고 생각만 갖고 있던 가설을 실제로 검증하면서 맞게 떨어져서 큰 역할을 한 것 같아 만족스러웠던 프로젝트이다.

임주성
안 되면 되게 하라